API-Design done right
Api-Design done right. Die Basics die gute APIs ausmachen. Kurz, einfach und verständlich.


Im letzten Post ging es um APIs und wie sie unser Leben besser machen können. Falls du es noch nicht gelesen hast empfehle ich dir den Post zu lesen und dann wieder zurück zukommen :)
Kurzes Vorwort
Zugegebenermaßen ist der Titel etwas anmaßend. Ich bin kein Entwickler mit Jahrzehnten Erfahrung oder habe schon tausende APIs erstellt. Ich traue mich aber zu behaupten, das ich weiß was ich tue und auch schon einiges an Erfahrung in dem Gebiet gesammelt habe.
Aber genug von dem Geplänkel. Im folgenden soll es um die Basics des API-Design gehen. Was man machen sollte, wieso und auch wie. Also los gehts!
Where to start
Meistens ensteht die Idee eine API zu erstellen nicht direkt. Man entwickelt vielleicht eine Anwendung und stellt fest, das man was zentrales bräuchte, was man auch mal wo anders benutzen kann. Klassicher Fall: eine Bibliothek, mit ein paar kleinen Helferlein.
Ich selbst kenne es, man fängt einfach damit an. Man macht sich nicht allzuviele Gedanken. Sprache oder Technik ist meistens klar, man benutzt was man immer benutzt. Doch wenn man hier nur etwas Zeit investiert, sich Gedanken macht wie man es umsetzt hat hier schon gewonnen.
Meine Angewohnheit dazu ist, sich mal grob im Kopf, oder auch schriftlich auf dem Block, dem digitalen Note-Taker oder whatever zu notieren. Was will man mit der API erreichen? Welche Zwecke soll sie erfüllen? Wo setzte ich die Grenzen?

Erst dann sollte man sich fragen, mit welchen Technologien man die API umsetzen will und natürlich auch kann. Gerade APIs zu entwicklen eignet sich meistens ideal um in neue Techniken einzusteigen. Meistens lernt man hier schnell manche Tricks und Tweaks für die Technologie oder setzt sich noch intensiver mit ihr auseinander.
Concept First
Okay wir wissen schon mal, wie wir unsere API entwicklen wollen. Genau an dem Punkt sollte man sich schon Gedanken über die Struktur machen. Denn eine gute API ist stabil und durchgängig. Ein einheitliches Konzept, eine Struktur, eine gewisse Art mit Fehlern umzugehen.
Wenn man das schon zu Beginn definiert, bleibt der "breaking changes every release"-Effekt wie ich ihn jetzt einfach mal benamse zumeist aus. Denn mal ehrlich: Welcher Dev hat Lust nach jedem Update seine Anwendung wieder anzupassen, nur weil der API-Ersteller meint er muss etwas komplett umbauen, ohne das wir einen Mehrwert erhalten?
Fehler-Handling
Ich beginne bewusst an dieser Stelle nicht mit der Dokumentation sondern dem Fehler-Handling. Das ist leider immer noch das schlimmste an den meisten APIs die ich bisher benutzen durfte und musste.

Fehler-Handling am Beispiel Rest-API
Im konrekten Falle für eine REST-API kann das bedeuten, das ich mich Standard-Konform daran halte immer einen möglichst passenden HTTP-Status zurückzugeben.
An der Stelle empfiehlt es sich auch eine feste Response im Fehlerfall zu definieren, im Idealfall global via zentraler Funktion. So gut wie jedes moderne Framework oder der Eigenbau muss damit klar kommen. Denn was bringt mir ein HTTP-Status, wenn ich nicht weiß was noch passiert. So kann z. B. ein 404 Not Found schon mal auf den ersten Blick zeigen, ah okay eine Resource wurde nicht gefunden. Doch ist die URL ungültig oder wurden keine Daten gefunden? - So etwas lässt sich dann doch nur mit einer einheitlichen Response abwicklen. Das kann z. B. als JSON-Response so aussehen:
{
"message": "Ticket with id 123 was not found!",
"status": 404,
"path": "/ticket/123"
}
So wird dem Aufrufer sofort klar was hier falsch gelaufen ist.
Fehler-Handling am Beispiel Klassenbibliothek
Das selbe lässt sich auch auf klassische Klassenbibliotheken anwenden. Ich nehme mal als Beispiel Java. Hier könnte unser Framework folgende Hierarchie haben, wenn wir als Beispiel eine Bibliothek nutzen, die Streams verarbeitet.
Die Exception-Struktur ist hierbei natürlich nicht die beste Lösung sondern sehr rudimentär um die Grundlagen zu veranschaulichen.
StreamException Basis-Exception
|-- StreamAccessException Fehler bei Zugriff/Verarbeitung
|-- StreamLockedException Stream ist gesperrt
|-- StreamProcessException Generischer Fehler bei der Verarbeitung
|-- StreamClosedException Stream ist geschlossen, unverarbeitbar
So kann relativ leicht ein sprechendes Fehlerhandling ermöglicht werden. Je nach Detailstufe, die abgefangen und verarbeitet werden soll, kann der Aufrufer selbst entscheiden wie viel Info er überhaupt benötigt.
Dokumentation
Kommen wir auch schon zur Dokumentation. Ein sehr wichtiges und teilweise leider immer noch unterschätzter Aspekt einer API. Auch scheinbar selbsterklärende Schnittstellen schadet eine Dokumentation in keinem Fall.
Zum einen lässt sich so ohne die Schnittstelle wirklich zu benutzen oder zu testen feststellen, was sie so kann. Im Zweifelsfall lässt sich daraus das eine oder andere Verhalten ableiten oder nachvollziehen. Hierbei muss man es nicht übertreiben, meistens ist weniger mehr, dafür das Richtige!
Dokumentation am Beispiel Rest-API
Für Rest-APIs gibt es mittlerweile zahlreiche Tools, die auch schon recht verbreitet sind. Eines hierbei ist API Blueprint. Hier wird via Definitons-File(s) deklariert und dokumentiert. Via Tool wird daraus dann eine handlichere Fassung in HTML-Form. An der Stelle muss ich gestehen, das ich persönlich mich bisher etwas davor gescheut habe, da mir hier der Aufwand etwas zu hoch ist seperate Dateien zu pflegen.
Ich persönliche nutze favorisiert Swagger. Hierbei gibt es auch die Möglichkeit die API via seperaten YAML-Dateien zu beschreiben. Es gibt jedoch für viele Sprachen einige grandiose Integrationen, dazu später mehr.
Zudem gibt es hier eine Web-UI nach dem Prinzip "Try it, before you use it". Hierbei lohnt sich ein kleiner Blick auf die Swagger-Demo des Petstore.
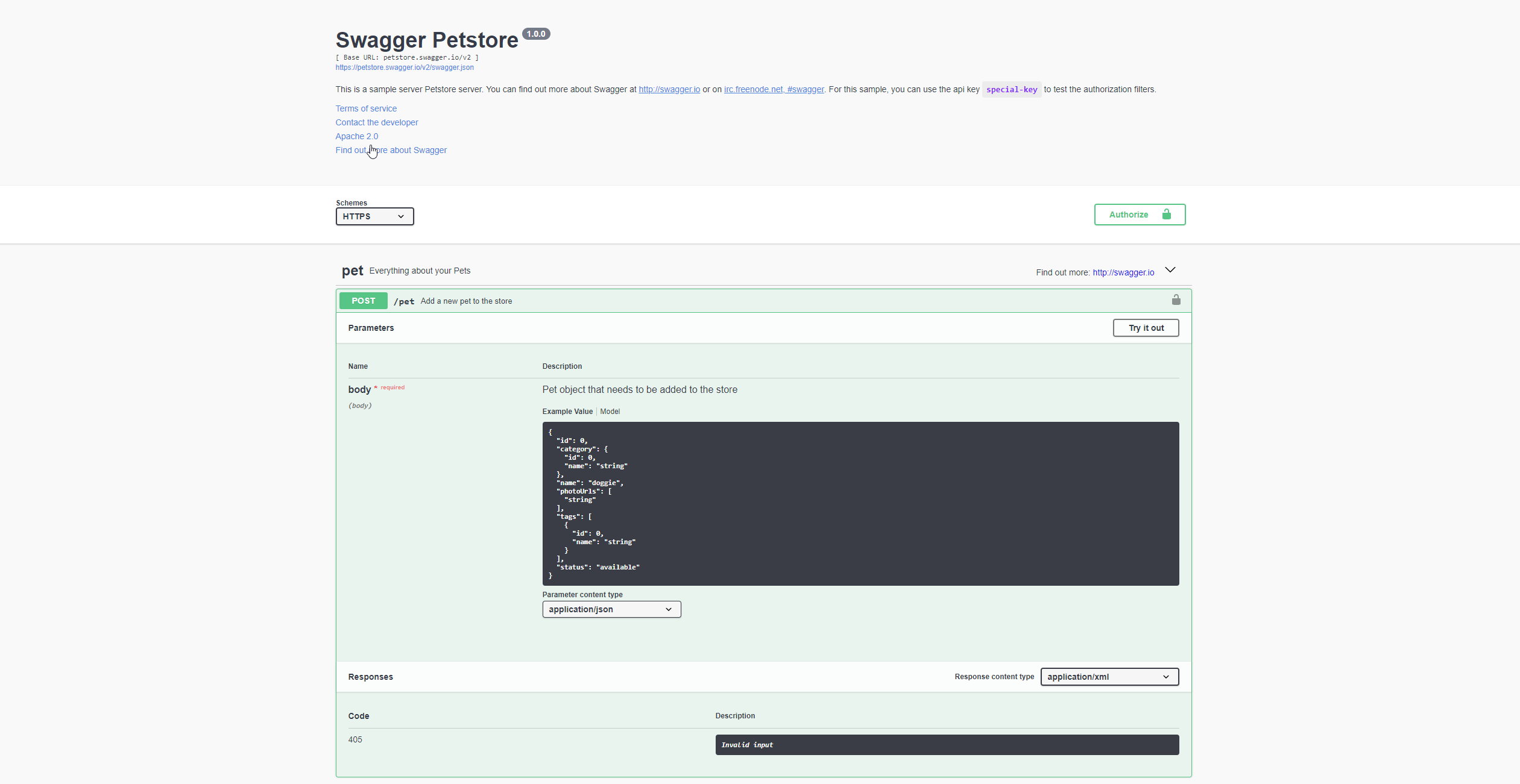
Der Vorteil hierbei ist, das sich die Oberfläche via CSS und etwas JavaScript ganz leicht nach eigenen Wünschen oder dem Firmendesign anpassen lässt. Trotzdem bekommt man hier eine für viele Entwickler vertraute und voll funktionale Oberfläche als Hybrid aus Doku und Try-It.
Da ich aktuell primär mit Spring Boot entwickle, ein Java-Framework das hier viel Potenzial zu "Autokonfiguration" hat, gibt es hierbei Starter mit denen ganz einfach im Source-Code dokumentiert werden kann. Das sieht dann z. B. so aus:
@Api("Ticket actions")
@RestController
@RequestMapping("/ticket")
public class TicketController {
// code
@GetMapping("/")
@ApiOperation("Get all tickets for the current user")
public List<TicketBean> getTickets() {
// code
}
}
Hieraus erstellt Swagger dann zur Laufzeit die entsprechende Sektion in der UI und stellt diese via API selbst unter /swagger-ui.html zur Verfügung. Für alle die lieber Tools via Postman nutzen wollen, gibt es entsprechende Integrationen.
So lässt sich idealerweise gleich am Source-Code selbst die API dokumentieren. Das führt in der Regel auch dazu das man hier immer die Logik, bzw. Dokumentation + API synchron hält. Hierbei ist die Dokumentation der API quais beigelegt. Entsprechende Deprecations werden übrigens hier auch übernommen und entsprechend dargestellt.
Dokumentation am Beispiel Klassenbibliothek
Bei Klassenbibliotheken bieten die meisten Programmiersprachen entsprechend bereits Tools frei Haus. Im Falle von Java ist es JavaDoc, für PHP gibt es einige Tools und Frameworks/Bibliotheken hierfür (z. B. phpDocumentor).
In jedem Falle helfen entsprechendene Kommentare im Source-Code, die so gut wie jeder bessere Texteditor mittlerweile auslesen und entsprechend neben der AutoComplete anzeigen kann.
Ein Beispiel spare ich mir an dieser Stelle, den Kommentare im/am Code sollte schon jeder mal gesehen haben ;)
Testing
Ja Tests sind wichtig! Hierbei gibt es verschiedende Arten seine APIs zu testen. In den meisten Fällen eignen sich hier Unit-Tests am Besten. Sie sichern, dass jede Komponente der Schnittstelle entsprechend tut, was sie soll. Bei einer sauberen Trennung sollte am besten für jede öffentliche Methode der API mindestens ein Test vorliegen.
Im Zuge von CI/CD lohnt es sich um so mehr Tests zu schreiben, denn so lässt sich automatisiert feststellen, ob eine Bibliothek stabil ist. So lässt sich das erfolgreiche Testergebnis an die Bereitstellung der API koppeln. So lässt sich in den meisten Fällen ein Crash auf Production Systemen oder irrevisiblen Versionen in diversen Public Repos vermeiden. Denn ist eine unsaubere oder nicht ordnungsgemäße API erst mal freigesetzt ist es meistens schwer die Nachwirkungen abzuschätzen.
Testing von Rest-APIs
Auch Rest-APIs lassen sich mitterlweile ziemlich einfach testen. Hierbei lohnt es sich meistens die Funktionen hinter dem Rest-Mapping via Unit-Test zu testen. Die Prüfung auf das entsprechende Verhalten nach außen, was Fehler-Handling, Status-Codes usw. geht sollte man auf Integration-Tests setzen. Hier gibt es eine Vielzahl von Mock-Bibliotheken mit denen man entsprechend eine laufende API simulieren bzw. für den Test hochfahren kann, gegen diese werden dann die entsprechenden Tests gefahren.
Es würde allerdings den Rahmen sprengen hier ein Code-Sample einzufügen oder noch spezifischer einzugehen. Deshalb empfehle ich dir entsprechend eigenständig die üblichen Quellen zu konsultieren. Für Spring Boot empfehle ich an der Stelle dieses Getting Started.
Testing von Klassenbibliotheken
Bei Klassenbibliotheken ist meistens eine Testabdeckung via Unit-Tests am einfachsten zu realisieren. Sie ermöglichen zudem auch eine schnellere Entwicklung, da nicht immer Dummy-Projekte erzeugt werden müssen, sondern es reicht, entsprechend einen Test hierzu anzustarten.
Hier lohnt sich auch das Konzept des Test Driven Development, da man sich erst vornimmt, was das Endergebnis sein soll um dann die Logik zu programmieren.
Ein Beispiel für Unit-Tests in PHP könnte z. B. so aussehen:
/**
* Unit tests for the stack implementation
*/
class ArrayStackTest extends TestCase
{
/**
* This test verifies that the push and pop logic for
* our custom stack implementation works as intended
*/
public function testPushAndPop()
{
$stack = new ArrayStack();
$this->assertEquals(0, $stack->count());
$stack->push('foo');
$this->assertEquals('foo', $stack->get(0));
$this->assertEquals(1, $stack->count());
$this->assertEquals('foo', $stack->pop());
$this->assertEquals(0, $stack->count()));
}
}
Dokumentation ist wichtg, aber nicht immer ausreichend
Egal ob Rest-API, Klassenbibliothek etc; die meisten APIs sind nicht so trivial, wie die oben aufgeführen Beispiele. Business-Prozesse sind komplex, meist mehrstufig. Und nicht jede API hat nur eine handvoll Aufgaben oder Funktionalitäten.
Beispiele helfen Neulingen mit der API schnell Fortschritte zu erzielen und ein Gespür zu bekommen, wie Dinge funktionieren. Und niemand weiß besser wie eine API funktionieren (sollte), als der Entwickler der sie erstellt hat, in dem Fall du!

Man muss nicht für alles ein Beispiel machen, aber gerade bei mehrstufigen Prozessen oder grundlegenden Konzepten sollte man sich bewusst die Zeit nehmen solche Beispiele zu erzielen.
Nicht selten kommt es vor das man beim Schreiben der Beispiele merkt, dass die Ideen, die so sauber und durchdacht erschienen doch nicht so praktikabel sind. Das kann man weder durch Tests, noch durch die Dokumentation verifizieren.
Wer nicht mal gerne mit seiner eigenen API arbeitet, sollte noch einmal überdenken, ob da vielleicht etwas faul ist. Das ist natürlich kein Garant, da natürlich auch ein sehr starker persönlicher Einfluß mitspielt. In vielen Fällen ist dass doch noch eine Stelle für den letzten Feinschliff oder Verbesserungen für die Usability.
Abwärtskompabilität
Ein großes Wort. Viele verbinden mit dem Wort jahrzehntelang historisch gewachsene Systeme. Andere evtl. einen großen amerikanischen Hardware- und Softwarehersteller mit drei Buchstaben.

Der Trend scheint bei manchen Neuentwicklungen zu "Rolling Releases" zu gehen, oder wie ich gerne sage "überrollende Releases". Da werden einem jedes Monat, jedes halbe Jahre vielleicht jedes Jahr tolle neue Funktionen hingeworfen. Natürlich ist da kein Platz mehr für altes Gerümpel. Ein Breaking-Change hier, eine Flut von Deprecations dort. Hier sehe ich das vielleicht etwas zu konservativ, aber wer von uns hat Zeit für so etwas?
Versteh mich jetzt nicht falsch, ich bin kein Fan davon alte Leichen von Version zu Version mitzuschleppen. Jeder Code hat ein End-Of-Life. Jedes Konzept wird eines Tages von einem besseren, vielleicht auch viel effizienteren ersetzt. Das ist normal und richtig. Doch eine gewisse Stabilität schafft Vertrauen bei den Entwicklern die deine API in Production oder das Hobby einsetzen. Für Firmen die ganze Systeme darauf errichten. Hier kann man einfach der Zeit geschuldet nicht so oft und viel updaten. Da ist es natülich toll wenn deine API relativ konsistent bleibt.
Wie kann man das z. B. erreichen? Dazu im folgenden zwei Ansätze grob erklärt:
Parallelbetrieb von verschiedenen Versionen
Mit diversen GraphQL- und Rest-APIs ist es relativ simpel zu versionieren. Facebook und Co. machen das bereits erfolgreich. Hier wird immer die alte Version einen definierten Zeitraum noch angeboten. Das schafft Zeit umzustellen und lässt sich planen. So etwas ist relativ einfach definiert, allerdings auch mit Mehraufwand verbunden.
Deprecation mit einem bestimmten Release
Stellt man fest das eine Funktion in den nächsten Version entfernt werden soll, bietet sich je nach Release-Strategie an entsprechend Funktionen als Deprecated zu markieren, einige Releases noch mit zu führen und entsprechend dem Hinweis aus dem Code zu einem definierten Zeitraum zu entfernen. Das gibt Entwicklern Zeit umzustellen.
Im Idealfall bekommt eine API aber mehr Funktionalität ohne sich von viel zu entledigen. Natürlich sind technisch bedingte Schnitte oder zur Umsetzung neuer Konzepte und Patterns Schnitte notwendig. Doch man sollte an der Stelle immer hinterfragen, ob das Pattern oder das Konzept den Aufwand für die Konsumenten der Schnittstelle wert ist.
Entsprechende Defaults bei neuen Parametern reichen in den meisten Fällen schon aus, um abwärtskompatibel zu bleiben. Wie bereits eingangs erwähnt, ist hier auch eine solide Struktur als Basis ein erstrebenswerter Vorteil, denn in diesem Fall bleiben komplette architektonsiche Veränderungen relativ gering oder zumindest nicht so häufig.
Versioning
Ein immer wichtiger werdendes Thema ist Versionierung. Ich persönlich setzte hier ziemlich lange, wie viele Entwickler auf Semantic Versioning. Details auf der Homepage von Semantic Versioning.
Kurzgefasst und ohne in die möglichen Erweiterungen einzugehen:
Major.Minor.Patch
Major: Ein großer Schritt nach vorne, mit Inkompabilitäten ist zu rechnen
Minor: Neue Funktionen, abwärtskompatibel
Patch: Ich habe einen Bug gefixt, abwärtskompatibel
Das Versioning lässt sich noch relativ beliebig erweitern, aber diese Basics haben sich heute etabliert und sind wie bereits erwähnt sehr weit verbreitet. So ermöglicht ihr jedem Entwickler eine schnelle Beurteilung mit was zu rechnen ist.
Vorraussetzung dafür ist jedoch das ihr euch strikt an die Regeln haltet. Sonst wird niemand mehr darauf vertrauen, dass entsprechende Versionierung sich mit der Abwärtskompatibilität deckt.
Bring it to the people
Die Beste API ist nichts wert, wenn es niemanden gibt der sie kennt oder benutzen kann.
Lizenzierung
Ein erster Schritt, sofern möglich, ist die API oder Bibliothek unter einer entsprechenden freien Lizenz zur Verfügung zu stellen. Nur den Code zu veröffentlichen macht ihn nicht automatisch für jeden ohne Risiken nutzbar.
Für alle Faulen unter uns, empfehle ich die MIT-Lizenz, die wie folgt lautet:
Copyright YEAR COPYRIGHT HOLDER
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
Kurzgefasst, ich gebe alle Rechte am Code ab, mach damit was du willst. Aber ich werde sicher nicht im entferntesten dafür haften. Das ermöglicht dem Nutzer der API sowie auch dem Entwickler eine kostenfreie, aber auch haftungsfreie Nutzung. Heißt für Sicherheitslücken im Code haftet im Schadensfall dann der Nutzende.
Für alle die sich unsicher sind, wie sie ihre API lizenzieren sollen kann ich choosealicense.com empfehlen. Da kommst du in wenigen Schritten an die Lizenz die genau zu dem passt, was du brauchst.
Die gängigen Git-Hoster bieten auch alle an entsprechende Files beim Einrichten oder via Template zu erstellen. Die Schwelle die API zu lizenzieren ist also sehr gering, und der Zeitaufwand liegt hier im Bereich weniger Minuten.

Natürlich spricht auch nichts dagegen eine API zum Beispiel zu kommerzialisieren, sei es um die Serverkosten zu tragen oder seinen eigenen Geldspeicher aufzufüllen. Jedoch empfehle ich hier sich das Ganze genau zu überlegen, und auch zu überdenken wie viel der Service bzw. die API wirklich Wert ist. Zudem solltest du hier alle rechtlichen Rahmenbedingungen checken.
Teile deine API
Stelle deine API in deinem Bekanntenkreis (bevorzugt Entwicklern ;)) oder deinem Haustier vor! Teile die Idee mit deinen Kollegen, hole Feedback ein. Lass dich nicht entmutigen, auch wenn scheinbar nur du selbst deine API nutzt.
Denn im schlimmsten Fall hast du Erfahrungen mit dem Thema gesammelt, das hilft meiner Erfahrung auch, wenn das nächste Mal das Framework der Wahl oder Bibliothek mal wieder an der einen oder anderen Stelle komplett unlogisch erscheint. Oder vielleicht auch wenn das nächste mal eine Liste mit Deprecations im Newsfeed auftaucht.
Ich persönlich konnte damit mein Haare ausraufen und den Ärger über API-Creator auf ein Minimum reduzieren. Oft lernt man eben erst solche Dinge zu schätzen, wenn man selbst einmal in der Siutation war eine gute API zu entwerfen, entwicklen und dokumentieren zu müssen oder dürfen.
The End
Ich hoffe ich konnte dir etwas weiterhelfen zum Thema API-Design. Natürlich wurden alle Themen nur angekratzt, da das Thema doch recht komplex ist. Dieser Post soll die Einstiegshürden etwas nehmen und eine grobe Vorstellung geben, was man bei API-Design beachten sollte. Natürlich gibt es noch deutlich mehr Wege und Kriterien, die wichtigsten solltest du aber hier einmal gehört haben.
Wenn du gerne ein Thema nochmal intensiver in einen eigenen Post sehen willst oder dich austauschen willst, verfasse gerne einen Kommentar! :)